
I Taught an AI to Predict Geopolitics. Then I Let It Calibrate Its Own Sources.
Reading Time: 4-6 minutes
This is a write-up of a system I built for my geopolitical intelligence operation. The domain is forecasting — not news, not analysis, but knowing what happens next. And the AutoScan is how I keep the signal clean.
The Job: Know What Happens Next
Most news consumption is rearview mirror stuff: something happened, here’s the story about what happened. Good readers can extract signal from that, but the news itself is always about the past.
Predictie works differently. It’s one of my many domain agents set up on my OpenClaw AI system. Its model comes from Predictive History — a YouTube channel that analyzes geopolitical events through the lens of civilizational patterns, elite competition, and game theory. Some people call that psychohistory, others call it structural realism. The label doesn’t matter. What matters is the question: given what happened, and given the incentive structures at play, what happens next?
At each heartbeat (about every 2 hours), Predictie scans 34 sources and creates or adjusts active predictions. Not headlines — probabilities. “Scenario A is 75% likely.” “This development shifts P-026 upward by 5 points.” Every prediction has a confidence range, an expiry date, and a falsification condition. The system is built around the discipline of probabilistic forecasting, not narrative journalism.
Here’s the /monitor mission control page:
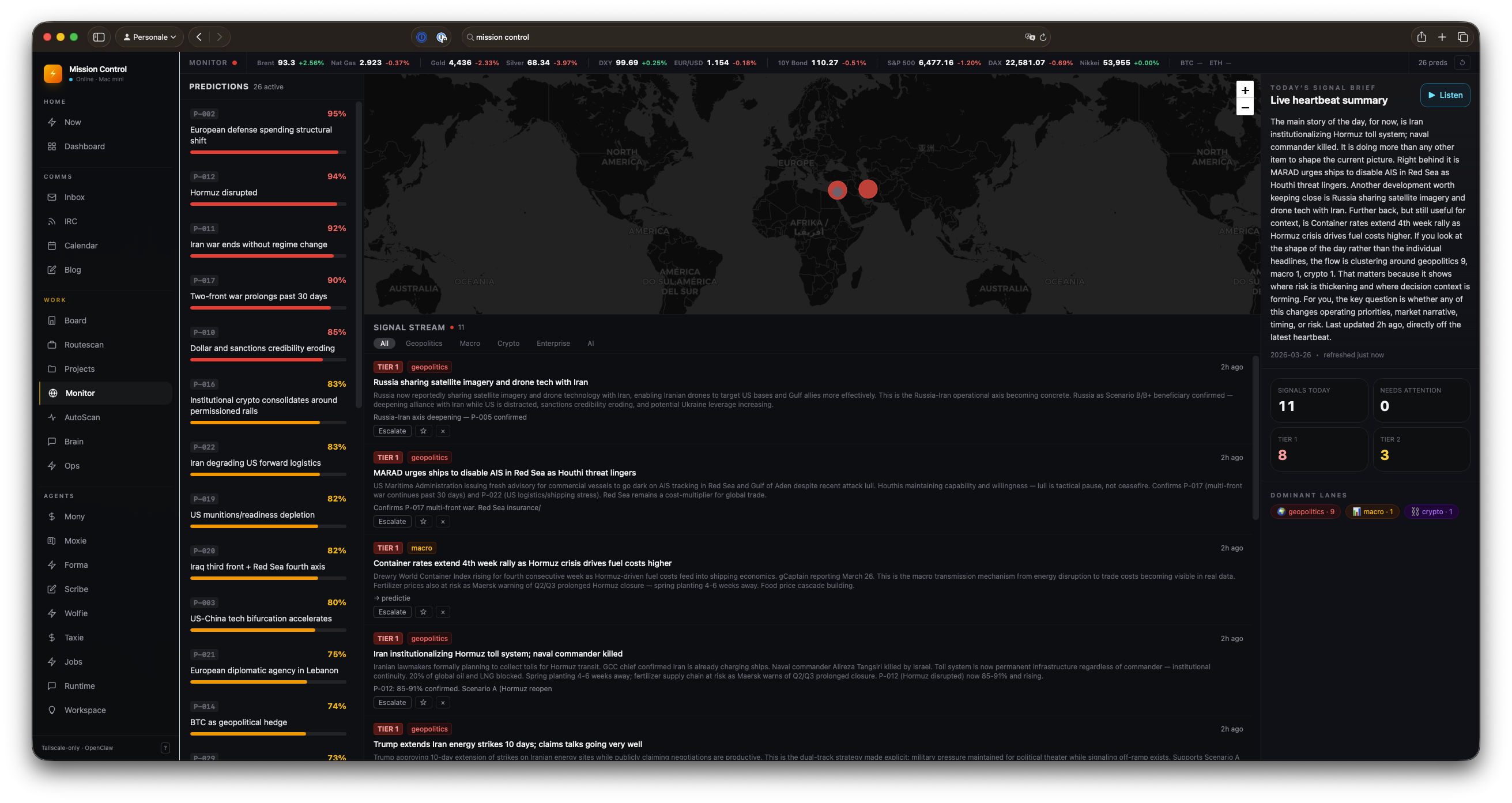
And the signal stream that feeds into it, updated every two hours.
Why Source Quality Matters More Than Volume
With 34 sources scanned every two hours, I had a volume problem I didn’t anticipate. Some sources fire constantly: they produce contextual articles, market coverage, general noise. Others barely register in volume but produce signals that actually shift probability estimates in the active predictions.
The gap between those two is everything.
A source can be prestigious, well-written, and entirely useless for prediction. Bloomberg publishes constantly. So do Financial Times and Foreign Policy. They’re in every intelligence feed. They feel important. And for two weeks, that’s exactly where they sat in my config.
Then I ran the numbers.
The Autoresearch Loop
A few weeks ago, Andrej Karpathy released autoresearch — a minimal research loop. The agent changes one file, runs a 5-minute training experiment, checks if the metric improved, keeps the change or discards it.
Agent changes train.py → runs 5 minutes → checks val_bpb → keeps or discards → repeat
The metric closes in minutes. By morning you have a better model.
The problem for intelligence is that geopolitical ground truth takes weeks or months. You can’t run a 5-minute experiment and know if a source is good. There’s no fast-closing feedback loop — only slow, noisy outcomes that may not materialize for months.
But you can use proxies.
The Proxy Metric
I score sources by: did this source produce signals that correlated with model updates?
signal_score = Σ (tier1_signals × 3 + tier2_signals × 1) × source_weight × information_gain
information_gain is the average probability shift in active predictions triggered by that source’s signals. TIER 1 gets 3× because model-moving signals matter more than contextual ones.
The 30-day check handles the obvious failure mode: a source could systematically push estimates in the wrong direction and still score well on the proxy metric. Every month I compare high-signal-score configs against actual prediction accuracy. If they stop correlating, it becomes clear.
Two Loops, Two Time Horizons
Backtest runs in under a minute. It replays 14 days of scan logs against a proposed source configuration. Iterate fast, measure, keep or discard. The backtest closes quickly because it’s replaying history.
Forward test runs for one week. Two configs run in parallel on the live feed. Which one produced more TIER 1s? Larger probability shifts in active predictions? The winner becomes the new baseline.
The human stays in the gate for structural changes — adding or removing sources — and for adoption decisions. The agent is an optimizer, not an owner. When the feedback cycle is slow, you want the system conservative.
Here’s the AutoScan page that runs this:
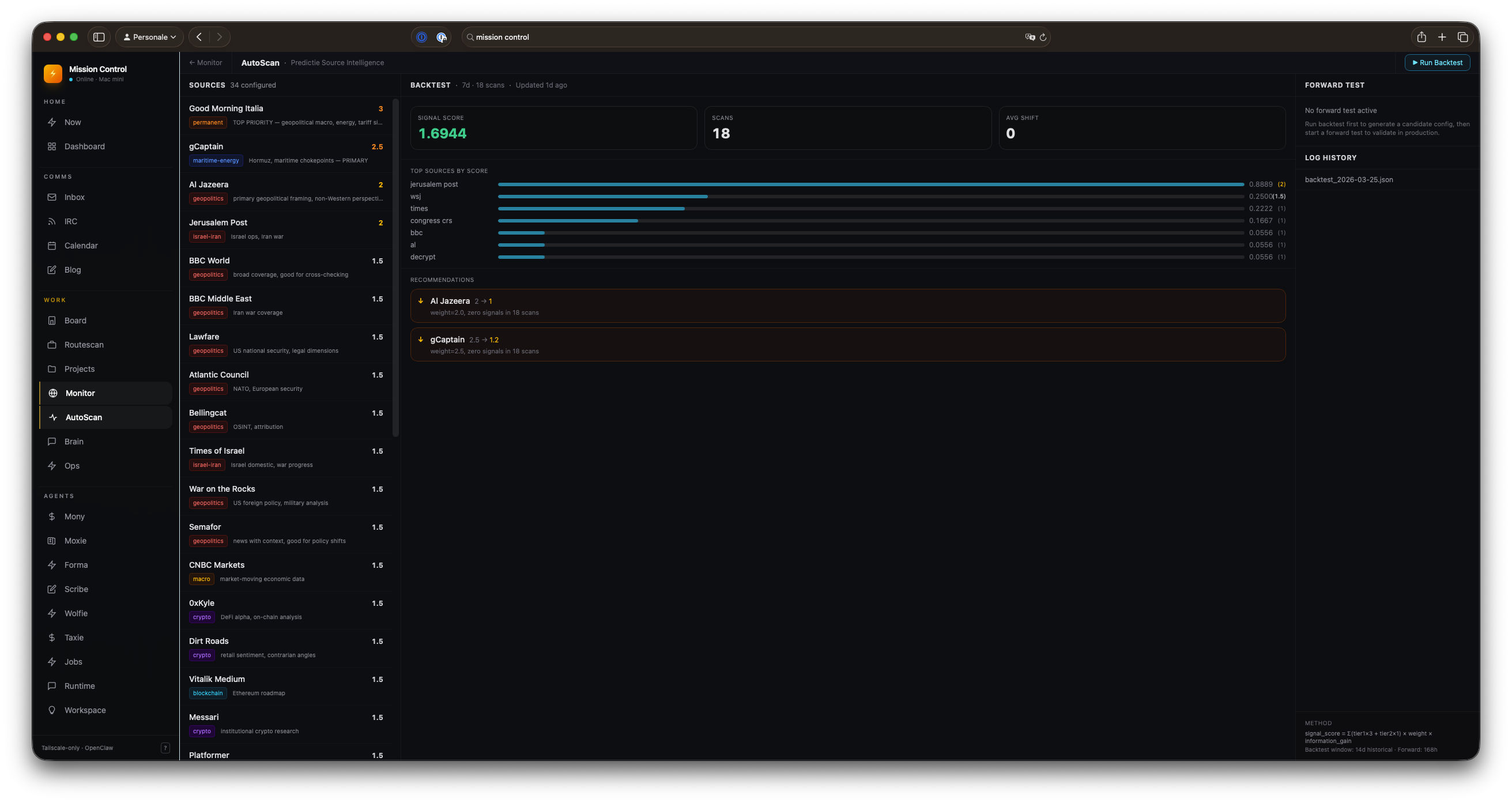
Sources on the left. Backtest results in the center. Forward test status on the right.
What the Data Said
Expected: Jerusalem Post, gCaptain, and Al Jazeera are the top three sources by signal score. They consistently appear in TIER 1 classifications and correlate with probability shifts in active predictions. My gut was right about these. Good — the metric is tracking something real.
Surprising: Foreign Policy, Bloomberg, Financial Times, and Predictive History (YouTube) all had weights of 2.0. Across 126 scans over two weeks, they produced exactly zero attributed signals.
Zero.
They were in the mix because they felt important. Because Bloomberg and FT belong in an intelligence feed, right? Because I read them and they seem serious.
They don’t. At least not for Predictie’s model.
Dropping their weights from 2.0 to 1.0 didn’t change the score — they weren’t contributing anything — but it stops them from diluting signals from sources that are actually firing.
The window problem: gCaptain showed zero signals in a 7-day window but strong signals in a 14-day window. The 7-day backtest recommended reducing its weight. The 14-day said don’t. Forward test is the arbiter here — and so far gCaptain keeps validating on the 14-day horizon. The rule will get more explicit if it keeps happening.
The Real Value
The value isn’t the marginal gain from weight optimization.
It’s the forced calibration.
Before this system, source quality was a feeling. Now it’s a number, a per-source breakdown, a recommendation with reasoning. The system surfaces the places where intuition and data disagree — and that’s where the interesting thinking happens.
It also creates a paper trail. Every weight change is logged with the backtest score that motivated it. Over time, this becomes a record of how the intelligence operation’s source priorities evolved, and whether that evolution tracked reality.
And sometimes the record shows that four prestigious publications were doing nothing for you.
That’s a good day.
The Architecture

research/autoscan/
├── SPEC.md ← methodology + metric definition
├── backtest.py ← replay scan logs, score config
├── forward_test.py ← A/B test on live feed
├── source-config.json ← current weights (agent edits)
├── program.md ← agent instructions (I edit this)
└── logs/
└── backtest_YYYY-MM-DD.json ← experiment history
The API is a SvelteKit server route that spawns the Python backtest as a subprocess and reads the latest log file. Dashboard sits alongside Predictie’s active predictions in the mission control panel.

Giacomo Barbieri
Head of Growth at Routescan. Building at the intersection of crypto infrastructure and AI agents.